What percentage of the Internet does Google index?
What part of the Universe can we see? To answer this question, we need to know or estimate the total size of the Universe.
It is impossible for us to estimate the size of the web without actually creating a big sample, but we can estimate the index size based on our own sites which we know well enough.
Today I stumbled upon one curious evidence I made few months ago, a screenshot of crawl statistics of one of my websites, as shown by Google Webmaster Tools.
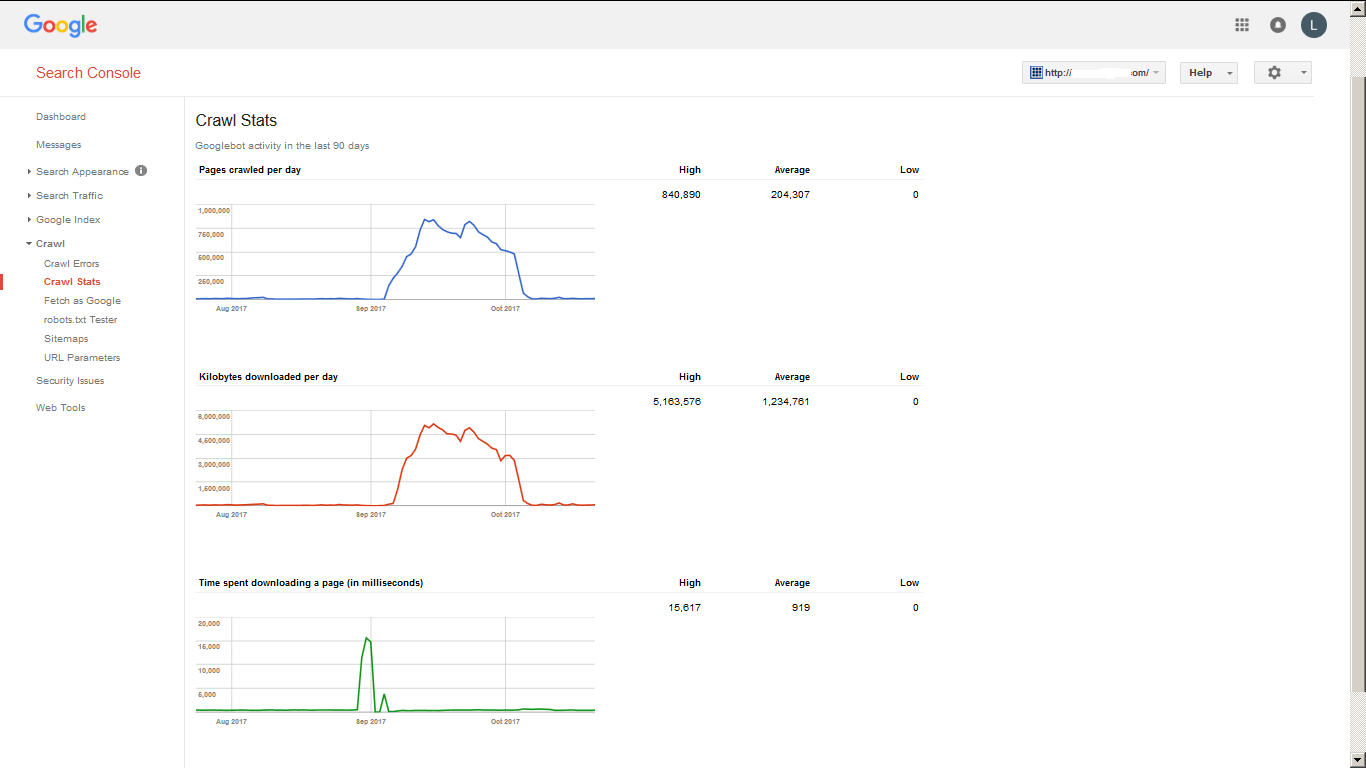
In case you think you are mistaken, yep, that’s over half a million visits daily, to a single site. This site is hosted on a shared host, so probably few hundred more sites there! Site is well optimized, so loading times were good enough. Nevertheless, you get an idea about how Google (dis)obeys netiquette.
To round it up, it crawled about 20 million pages during that month. ‘Normal’ crawl rate for that site is few thousands of pages per day, so hundred times less, or few tens of thousands per day when it was published. I did something with .htaccess file just before that peak, but details will remain a secret..
Anyways, how big is that site actually? For any practical purposes it is safe to say that it has probably infinite number of pages as it has bunch of filters and parameters and you can generate huge number of combinations with those. The content they generate is not that unique, so lots of overlaps with already viewed pages.
Anyways, Google crawled 20,000,000 pages in one month. It showed about 2,000,000 pages in its index at that time. And google search with ‘site:’ operator showed about 200,000 results.
So this gives you an idea, it crawls a small portion of the infinite web (some sections of this site, more important ones, it completely ignored!), stores in the index only those deemed worthy enough and unique enough, and shows to users even less.
To be fair, one should also analyze a site of finite size, and I’ve done that as well. Depending on the popularity and backlink profiles, Google misses pages there as well, or if not missing completely, attaches them in the index to queries so obscure which retrieve only a handful of web results. It is like having a fingerprint, or a combination of phrases from that pages which are unique to that page only, and ignores many of the other words from the page which are more common for the rest of the web. And this makes sense, it reduces the index size, and keeps only more relevant pages in the index for more common word combinations.
UPDATE:
I didn’t go into too much technical detail above, but with the following illustration I will scratch the topic of recent google algorithm trends.
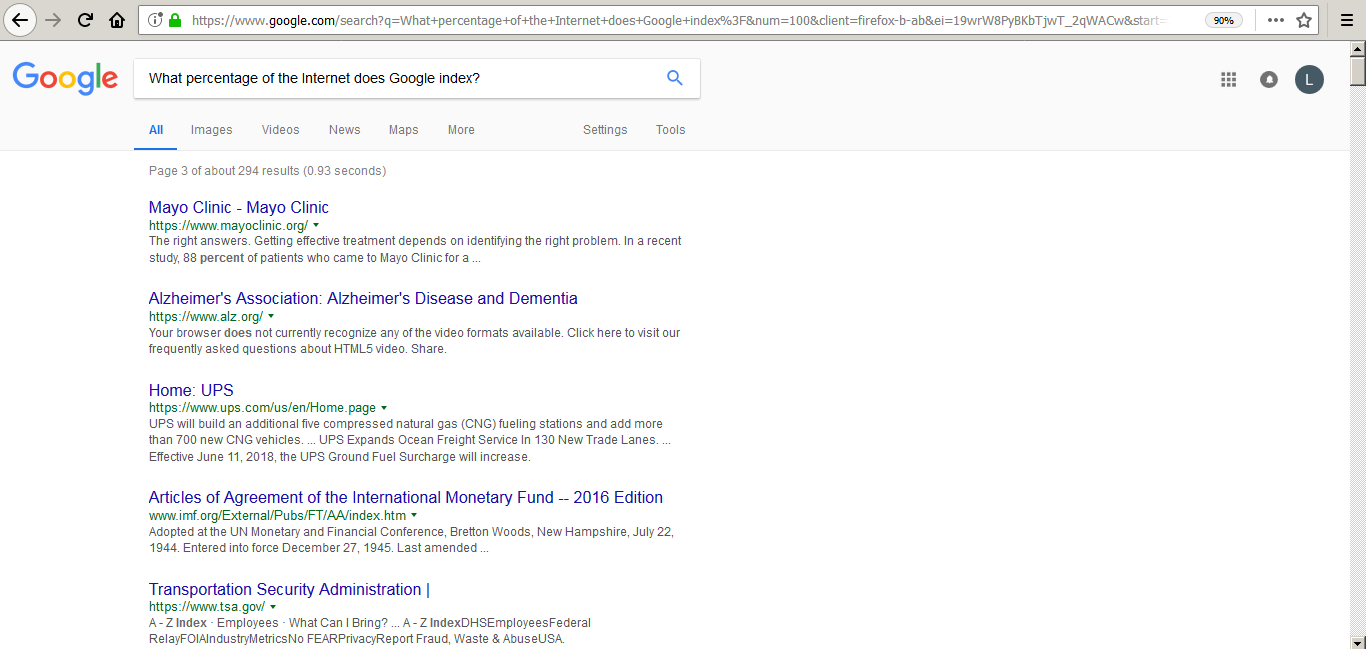
As you can see in the screenshot, I googled for the title of this post, and on the third page I got entries for Mayo Clinic, and Alzheimer site. Hmm. Alzheimer can be perceived in broad sense as a knowledge retrieval system (failure), and Mayo as well is most likely found in Alzheimer graph vicinity. So even though there are so many more relevant results on Google for the above title, they do not come even close in regards to backlink strength to Mayo Clinic. In other words, the brutal normalization of concepts and synonyms being done by Google algorithm is placing the Alzheimer in the same basket as (web information retrieval) index, and backlink strength for Alz sites is way above backlink strength for ‘index percentage’ sites. Given that Google relevance (IMHO) matched what should not have been matched, we got the results as is seen above.
In a nutshell, that is how Google is dealing with infinite information on the web, it over-zealously places various concepts in the same basket and provides ranked pages per basket, not per individual concepts. Kind of…








related:
Category: technical-seo Comment »