Food for Thought
May 8th, 2020 — 7:47pm
3 concepts, 1 dominant..
If you don’t know which one, I will help, the least frequent one.
tf-idf at work.. crude vector normalization, and poor diversification of results.
search engine obsession
3 concepts, 1 dominant..
If you don’t know which one, I will help, the least frequent one.
tf-idf at work.. crude vector normalization, and poor diversification of results.
Update:
In the last few years I have noticed it has become much harder to rank sites on Google. I knew it was in part due to using machine learning in ranking where things are based much more on big data statistics and less on common sense factors.
However, a recent whistleblower video illuminates why some sites may not rank as high or even be completely removed from search (or the platform all together). Following video has been removed from all major video sharing platforms, so it is quite important to see.
Google insider with hidden cam.
It is so important that some of the responsible people from Google have been called to congressional hearing. Super important points were made by the congressman:
I would add a few more points. Continue reading »
Query: https://www.google.com/search?client=firefox-b-1-d&q=Top+52+places+to+see+in+San+Bernardo
Results: Top 52 places to see in San Bernardo – Google Search
Just keeping this for future reference, to see if this is temporary experiment on their side, or permanent bug.
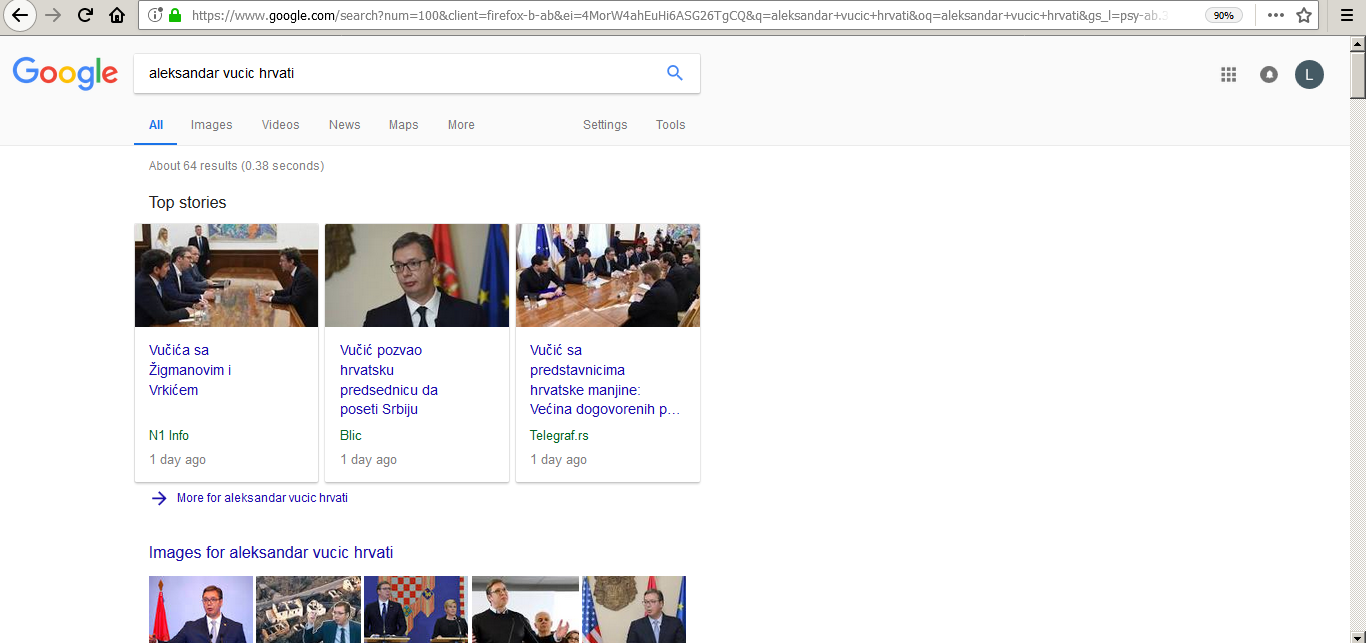
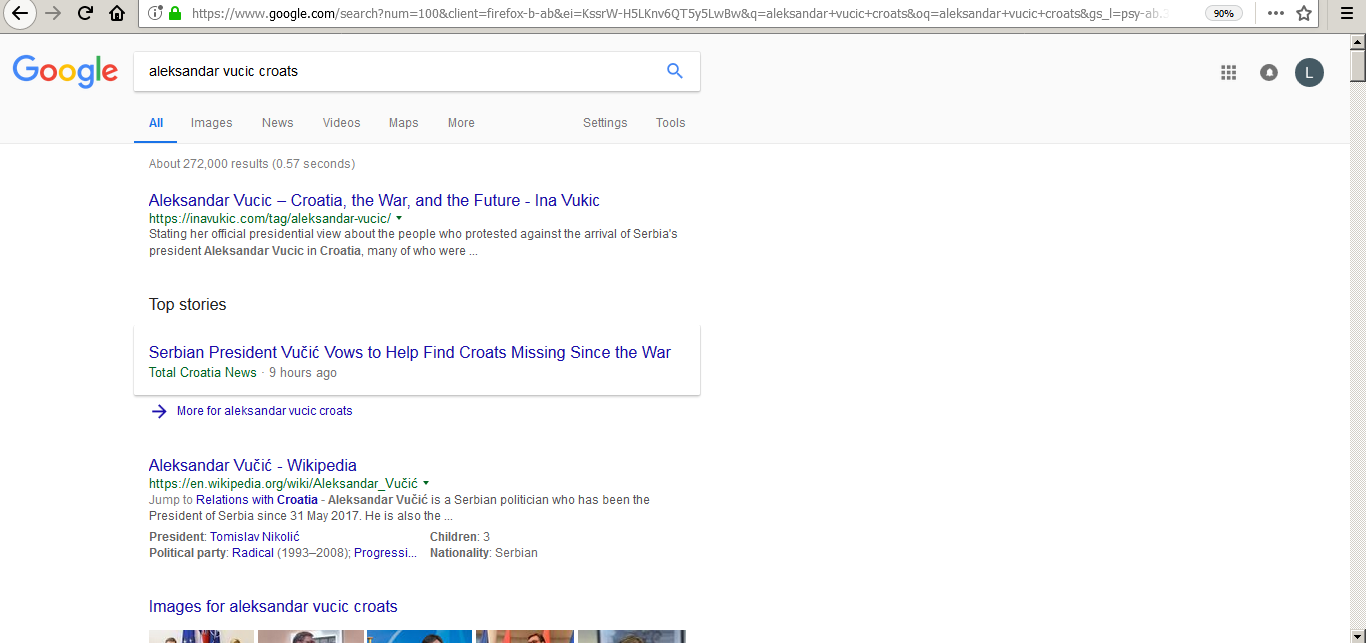
Recently a friend told me that all results were removed from Google for searches related to current Serbia’s leader Aleksandar Vucic (AV) and Serbia’s neighbours Croats.
AV used to say many bad things in regards to Croats during the wars in ’90s, and since he is pro EU oriented, this localized censorship can be perceived as an attempt to ‘help’ forget the past and love thy neighbour.
Very interesting case of censorship. For a query from Belgrade, Serbia, Google returns 63 results only for a phrase in Serbian language aleksandar vucic hrvati, while quarter of a million of results for English language query where ‘hrvati’ is substituted with ‘croats’: aleksandar vucic croats.
What part of the Universe can we see? To answer this question, we need to know or estimate the total size of the Universe.
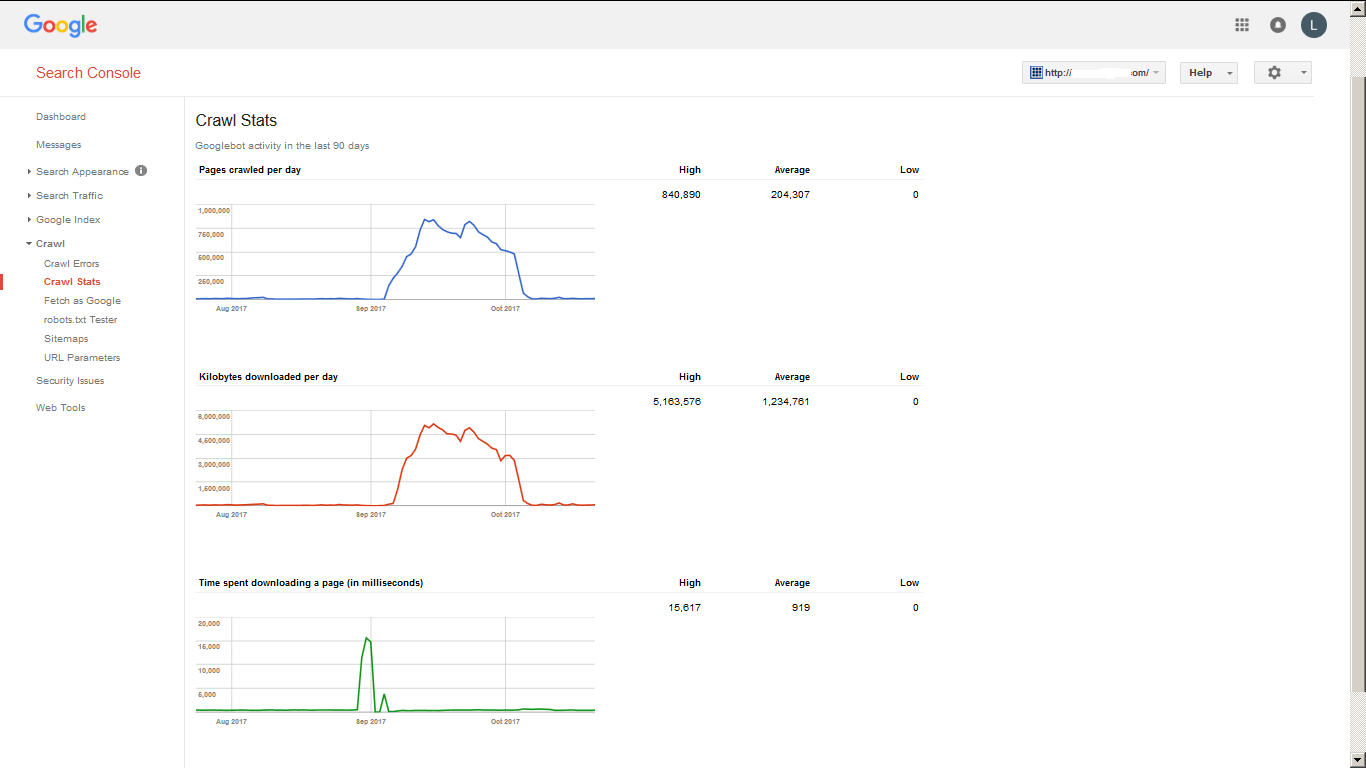
It is impossible for us to estimate the size of the web without actually creating a big sample, but we can estimate the index size based on our own sites which we know well enough.
Today I stumbled upon one curious evidence I made few months ago, a screenshot of crawl statistics of one of my websites, as shown by Google Webmaster Tools.
It is amazing how much search engine technology evolved during the past decade. I remember when I was reverse engineering how they work by simply doing thought experiments based on common sense and how I would implement similar things (I do have a computer science related background). Often I was able to test my hypothesis with actual experiments, but sometimes experiments were not feasible.
Thousands of engineers, scientists, inventors, and scholars are researching and contributing to this field, directly and indirectly. That is millions of man hours of dedicated and passionate work! Web Information Retrieval is such a rich area of human knowledge and full of impressive findings, both in sense of cool ideas, and impressive engineering and scalability. How come that most available SEO tools rely on such old concepts as are keywords? Continue reading »
How Yoga helped me refresh my blog SEO knowledge
UPDATE (January, 2018): Apparently, pingback service is overwhelmed with automated blog posts which are becoming more and more common on the web, and as a consequence regular posts cannot always get real-time attention the way they used to.
I tried yoga in LPAC Chicago several years ago, and honestly, even though I went for a year, I wasn’t impressed. Recently I tried Bihar Yoga classes in Belgrade (Joga Beograd), and I must say that they are just incomparably better. Teacher Milan has M.D. and has also lived and studied yoga (and acupuncture) in India. Unlike most contemporary yoga instructors who superficially learn in a year or two how to teach, Milan has a deeper understanding of why and how each asana should be done, their sequences, pauses, etc. I liked these classes so much that I offered to help out with the site they didn’t have.
Even though unfinished, we decided to publish the site, just to start appearing on search engines. Site has been online for few days now, but there are two problems:
First problem I kind of expected given the site is brand new. However, what surprises me is that it ranks low even for the domain name phrase query. In the past I noticed such thing happen only for quite competitive phrases. “Joga Beograd” without a detailed analysis didn’t seem to be such a competitive phrase.
Second problem however is much more interesting.
Comments Off on Post vs Page SEO | SEO Tips
This is a video which provides a glimpse into the complexity of Google inner workings. A search quality group meets to discuss a proposed change. Google has well over 10,000 engineers, and more than 1,000 person-years have gone into the search algorithm development. You may wonder why only 1k years when there are 10k engineers and Google was founded more than 10 years ago – shouldn’t it be 100,000 person-years, or at least a linear average as the initial number of engineers was 2? Well, search is not the only thing they do.
What is really cool here is that Google has a whole team dedicated to figuring out, implementing, and testing the change that will affect only 0.1% of queries. Even these ‘tiny’ changes with ‘minor impact’ get attention of employees of all levels – from young engineers to VPs.
You can read more about it at official Google blog.
There is a lot of commentary on the web about Wikileaks and its founder, and you can spend days reading stuff and watching videos. I did that. Here is selection of, in my opinion, some of the best videos and links that will make you instantly well informed on the topic – its background, motivation, vision, technology, affairs, legal issues, consequences, freedom, rights…
Background information: Wikirebels (documentary in 4 parts – one hour total)
Continue reading »
Comments Off on Wikileaks & Julian Assange | Uncategorized
I wrote before about the rel nofollow monstrosity. It seems Google guys did finally realize something is terribly wrong with their invention. What Google anti-SPAM engineer Matt Cutts told us the other day is this:
Instead of preventing a “PageRank leak” (read: pathologically saving every drop of the inbound linking credit that a site gets) as can be seen in this “rel NoFollow” article, Google decided to simply exclude the PageRank which is nofollowed from the equation, effectively, reducing the size of PageRank that circulates through the site (and the web). This will, by the way, introduce some global level disturbances in the page-rank matrix, one of the major algorithms in the google rankings (even thought the number of nofollowed links is less than 3 percent, as they mostly come from big sites).
Is this change good or bad?